
Wrapping up my final assignment in CS106B, Programming Abstractions in C++. I've enjoyed this class immensely and has given me a much stronger working knowledge of programming. It's amazing what you can do when you know how to think about data!
The last assignment is called Trailblazer. It focuses on two sections: 1) pathfinding, and 2) maze building.
Pathfinding
I was tasked with implementing Dijkstra's algorithm. It's an algorithm that finds the shortest path from one node to another by searching along a graph. It takes an unvisited node with shortest distance, calculates the distance to neighboring nodes by following the path through it, and updates the distance to those nodes if they are smaller than before. Here's a handy animation.
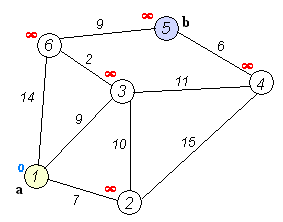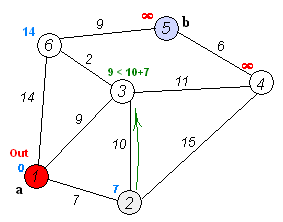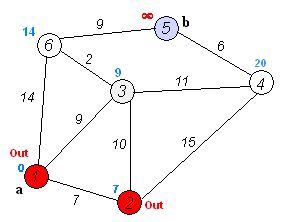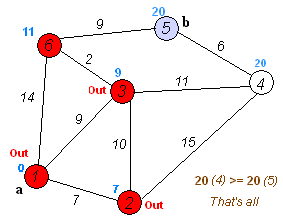
As is typical for the introductory CS courses at Stanford, we are not simply asked to merely code the algorithm. Instead, we must implement it as part of a grander task. In this case, they provide us with a start program that generates a random terrain with variable elevation. (White regions are mountains, dark regions are valleys.)

We were to use Dijkstra's search to find the shortest path. The "cost" of the path is evaluated based upon a provided cost function that considers elevation change and whether it's moving cardinally or diagonally. We also color the cells that are queued and then visited, to see how Dijkstra's algorithm progresses. The end result is quite visually interesting. On a relatively flat playing field, it becomes clear how Dijkstra's is (essentially) a breadth-first search algorithm.
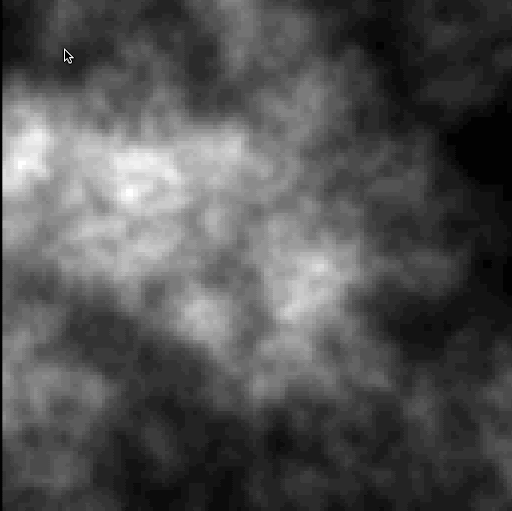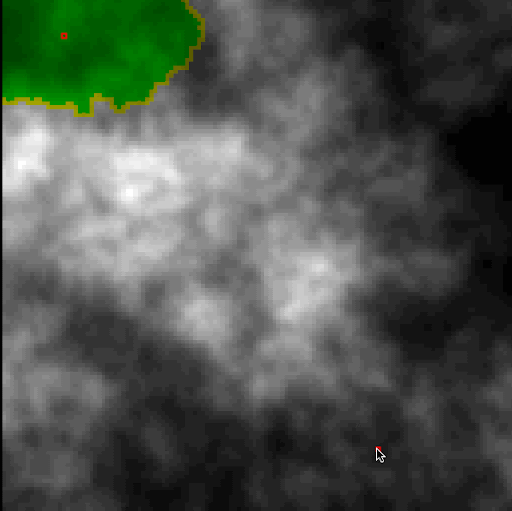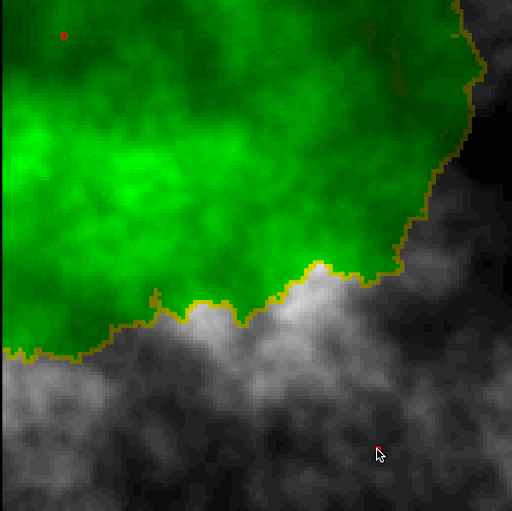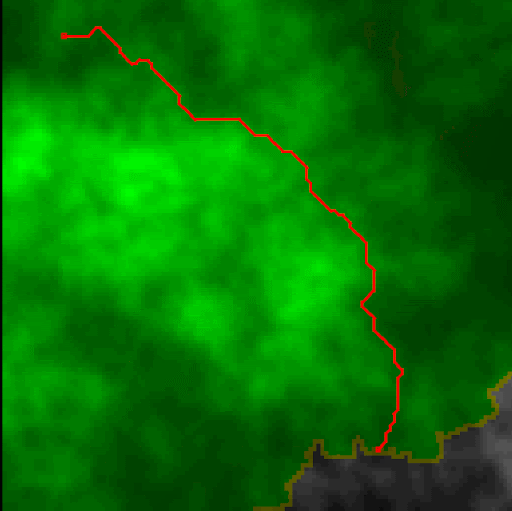
It can also be used to solve mazes.
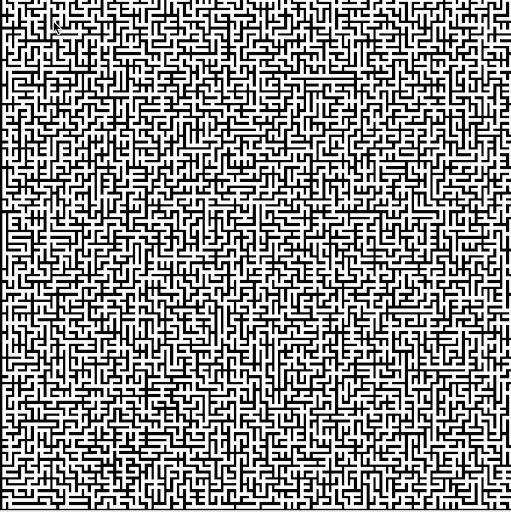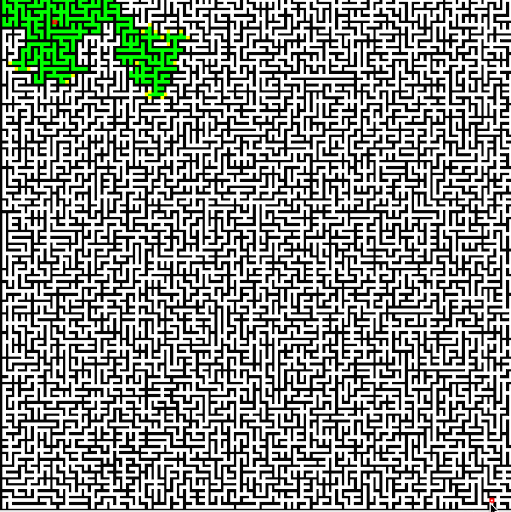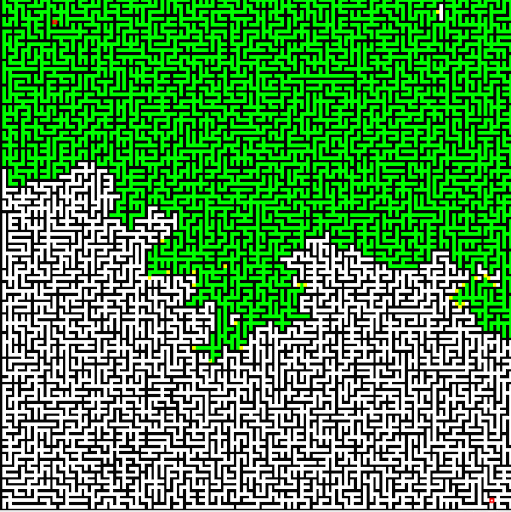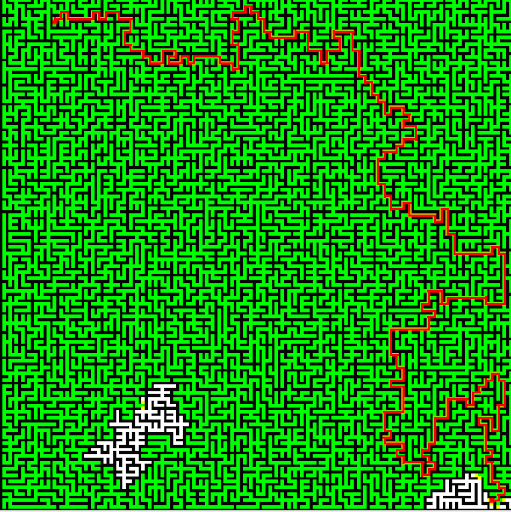
Dijkstra's algorithm clearly lacks a broad understanding of the problem, as with the terrain search. It expands all the way outward in every direction, worried that maybe some other path with a shorter distance just might happen to be the end node. The algorithm can be augmented with a form of "intelligence," a heuristic that helps it to prioritize nodes that get closer to the end node. Such heuristic functions may be something as simple as the distance "as the crow flies" from the intermediate node to the end node. With such a heuristic, steps along a path leading toward the end node can be prioritized over nodes a short distance away but in the wrong direction because they are given a lesser candidate distance.
The augmented algorithm, called A* search, clearly performs better.
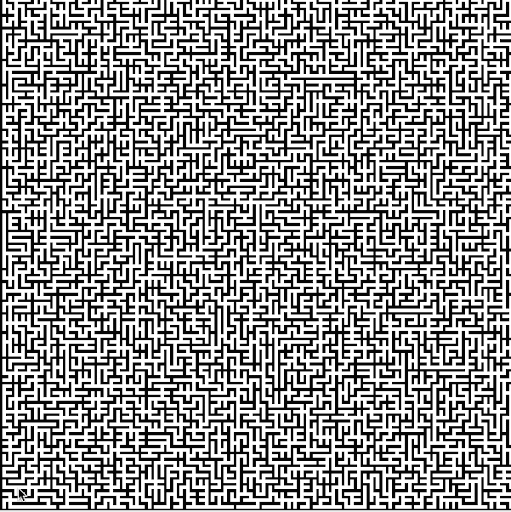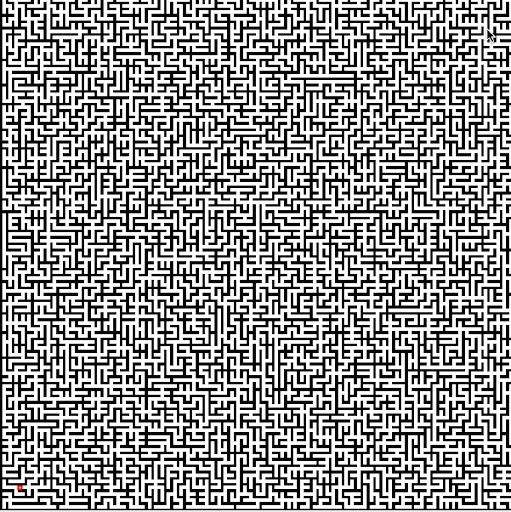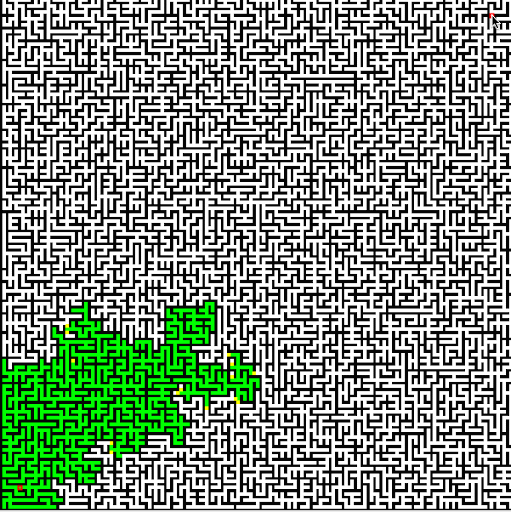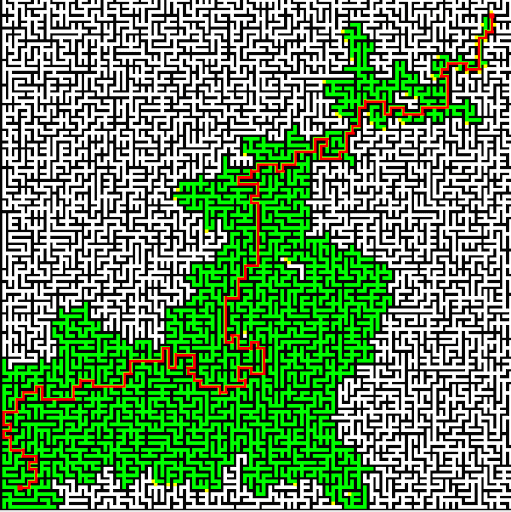
Of course, it doesn't always work perfectly.
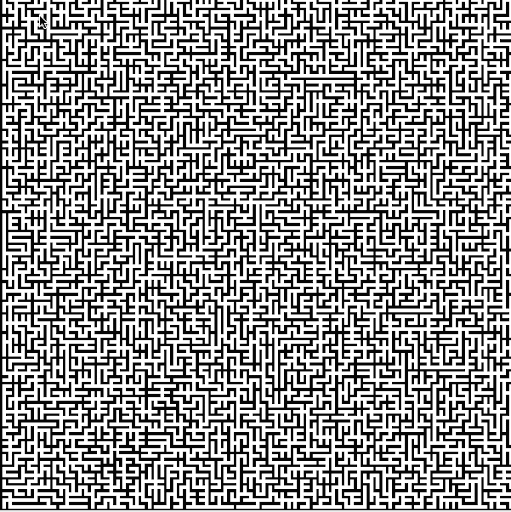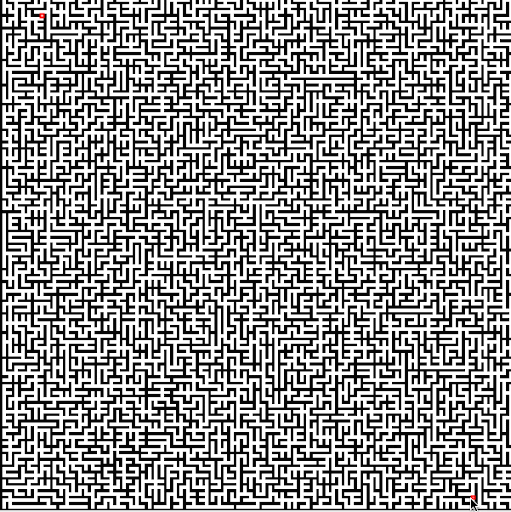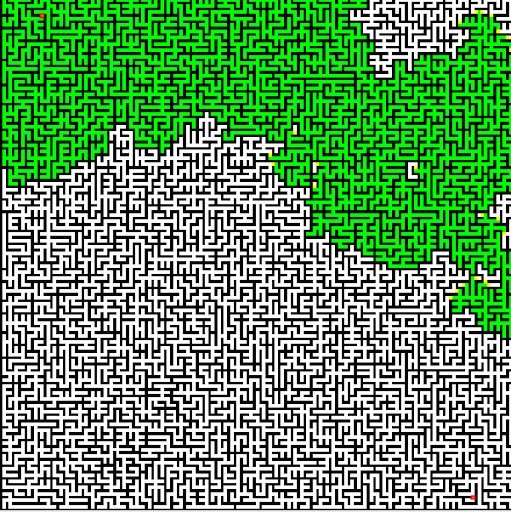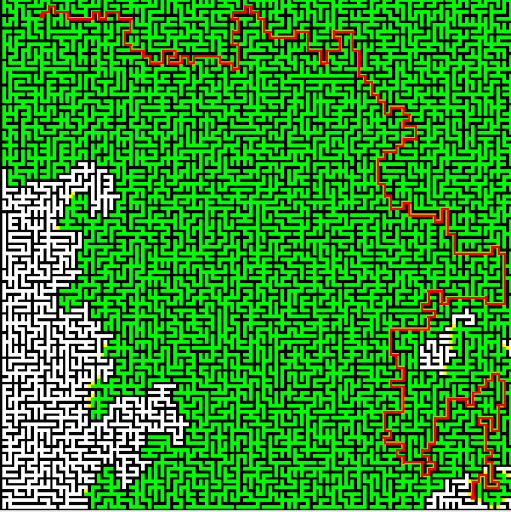
And on the terrain…

My favorite aspect of this last animation: the way it shoots out tendrils on its path toward the end node. It clearly is "seeking" toward the end point, it has a guess as to where it might be located.
Gorey implementation details for the programming-literate:
-
Wanting more practice with structs and pointers, I created a struct
Nodeto track whether the node has been visited, the distance associated with the node, and the parent node (not a pointer, just a Location). This setup had the added benefit to not have multiple data structures that each stored one piece of data (e.g. node -> distance, orSet<node>of visited nodes, etc.). -
A
Map<Loc, Node*>parent map that used a node (Loc) as the key and pointed to the parent Node. -
Once the end node is processed, the parent map is flattened and its path reversed (because a parent map traces from end to beginning, it must be reversed to reveal the path from beginning to end).
I was less satisfied with my implementation here. Upon reflection, I don't think pointers were necessary. I'm so accustomed now to only using pointers to refer to my arbitrarily created structs, that it feels foreign to use them as a regular type. I could have made the parentMap as Map<Loc, Node> and it would've worked just fine, I think.
For some reason, the algorithm bogs down in the final stages and slow dramatically more than the demo version provided by Stanford. Not quite sure what's going on there. I tried implementing using HashMap instead of Map to get O(1) access to the nodes, but that made no difference.
I was pleased with my insight to try out storing all my information in one place with a struct. This approach has not been strongly emphasized through the course, but I think it's a handy tool.
Maze Building
The second portion of the assignment was to implement an algorithm that generates mazes. We used Kruskal's minimum spanning tree algorithm. Given a graph of nodes and edges with associated weights (e.g. distance), a "minimum spanning tree" is a tree that connects all the nodes with the lowest cost.
Kruskal's algorithm is crafty. It starts with setting each node to be in a separate cluster. Edges are viewed in order of priority, i.e. least cost. If the edge has two nodes in separate clusters, the clusters are merged and the edge added to the resulting tree. In this way, cycles are avoided: a cluster means the nodes are connected, so adding an edge to two nodes within the same cluster would create a loop.
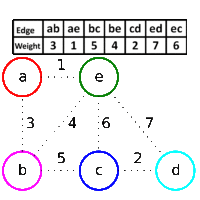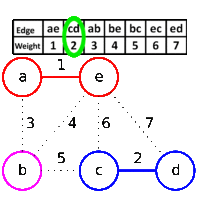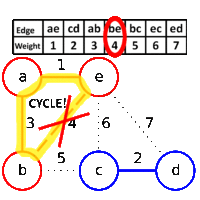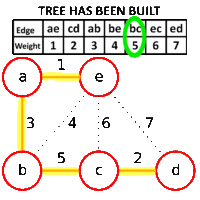
For example, if you take a grid graph and assign random weights to the edges:
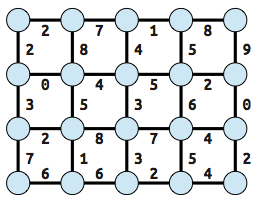
Kruskal's algorithm produces this result. (Actually, there's an error here: the edge "4" between columns 2 and 3 should be included, instead of "6.")
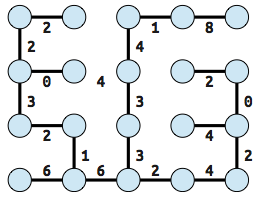
The neat thing about minimum spanning trees of a grid graph is that they can be used to generate a maze. The edges are inverted and become the "solution" or path through the maze that connects all the nodes together.
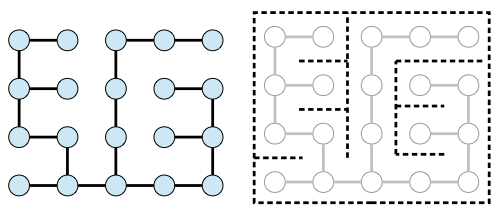
Results from my program aren't anything you haven't seen already; it just allows me to generate mazes at random.
For the programming inclined, here's some more gorey details about my implementation.
- Edges were tracked using
Sets. Edges are a type defined as having a start node and an end node (neither were pointers). - The cluster a node belongs to is tracked with a
HashMap<node, int>. - The nodes a cluster contains is tracked with a
HashMap<int, HashSet<node> >. - Merge was a simple process of taking the union of sets, and deleting the excess entry from the
HashMap.
This implementation leans on data structures presented on class, namely the HashMap, HashSet, and Set. I have also been pointed to the Union Find datastructure, which will be my next extension to keep learning.